Le Pétaoctet de données expérimentales a été atteint !
Après le 13 septembre 2006, date à laquelle a été stocké le 1er octet de données expérimentales sur DIFFABS, près de 12 ans plus tard, celle du 17 juillet 2018 restera aussi mémorable pour SOLEIL. En effet, c’est ce jour-là que le Pétaoctet de données expérimentales stockées a été dépassé.
Le pétaoctet est une unité de mesure de capacité de stockage de données qui équivaut à 10 puissance 15 octets (1 Po = 1015 o). Cela représente 55 fois la bibliothèque du Congrès américain si elle était numérisée, mais aussi ce que le cerveau humain (souvent comparé à un ordinateur) est capable de stocker pour une consommation de seulement 20 watts !
Depuis 2008, en utilisant différentes générations de détecteurs, les scientifiques et utilisateurs de SOLEIL produisent de grosses quantités de données qui alimentent la connaissance, les découvertes et l’innovation. Les performances de plus en plus élevées de ces équipements font que l’infrastructure de stockage joue un rôle éminent dans leur fonctionnement, permettant ainsi de collecter et d’analyser davantage de données et de faire progresser la science. Cela a nécessité plusieurs évolutions importantes de l’architecture informatique de SOLEIL, installée initialement en 2006.
Cependant, manier un tel volume de données présente des difficultés et gérer 1 pétaoctet constitue un défi : les données ne sont pas figées, elles ont un cycle de vie, se développent et vieillissent. Après leur création, il est nécessaire de les stocker, de les archiver pour des utilisations ultérieures et de les protéger à chaque étape pour éviter toute perte. Ces tâches se compliquent à mesure que le volume des données scientifiques augmente.
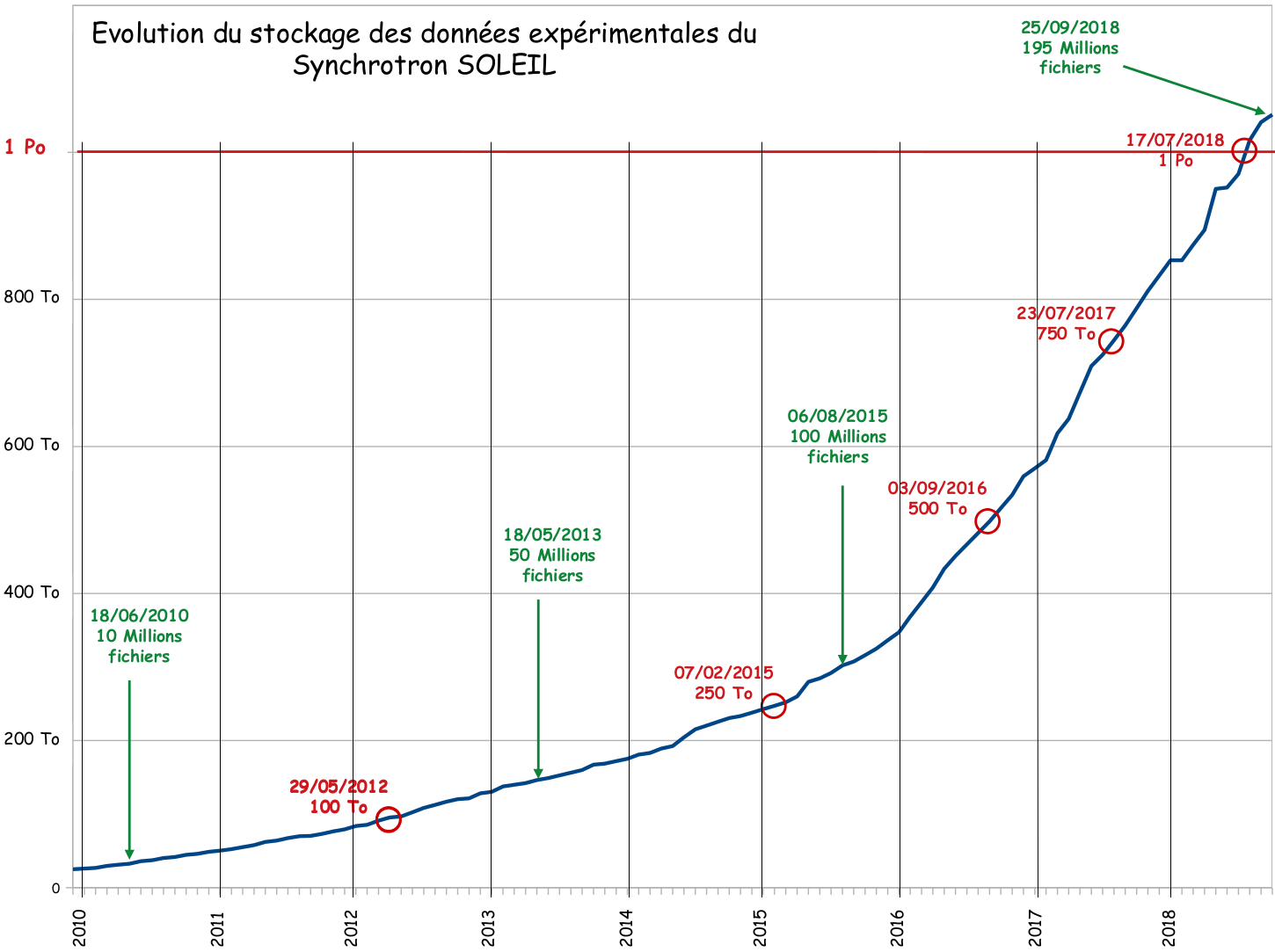
A SOLEIL, la progression a été régulière sur ces 10 dernières années, avec une accentuation très significative ces 3 dernières années depuis l’arrivée des derniers détecteurs haute performance et des techniques d’acquisition multi-détecteurs. En date du 20 septembre 2018, le volume stocké est de 1,05 pétaoctets pour 195 millions de fichiers, soit une moyenne d’environ 5 mégaoctets par fichier.
Même si toutes les lignes de lumière sont utilisatrices de la plateforme de stockage dite RUCHE, certaines sont plus « consommatrices » ; sans surprise, ce sont essentiellement les lignes de cristallographie des macromolécules (PROXIMA-1 et PROXIMA-2A) et de tomographie (PSICHÉ, et bientôt ANATOMIX) qui produisent les plus gros volumes de données. En effet, ces lignes utilisent des détecteurs "bidimensionnels", c'est à dire qui permettent d'acquérir des images dont chaque pixel contient une information, et enregistrent un grand nombre d'images pour déterminer les propriétés des échantillons. On peut s'attendre à ce que ces lignes de lumière soient bientôt rejointes par celles qui réalisent des expériences par "balayage", comme NANOSCOPIUM. Sur ces lignes, le faisceau de rayons X qui arrive sur l'échantillon pour le sonder ne mesure que (quelques centaines de nm)2. Pour caractériser l'échantillon, celui-ci est déplacé horizontalement et verticalement par rapport au faisceau, et plusieurs informations sont enregistrées "au vol", ce qui revient à créer une image avec un très grand nombre de pixels.
